Objects4 Dataset

View a few objects in your
browser
(a WebGL-compatible browser is
required, eg. Chrome, Firefox).

What: A dataset of 631 objects scanned with a Velodyne HDL-64E LIDAR.
Where: Sydney CBD.
Why: To test 3D feature extraction and object classification algorithms.
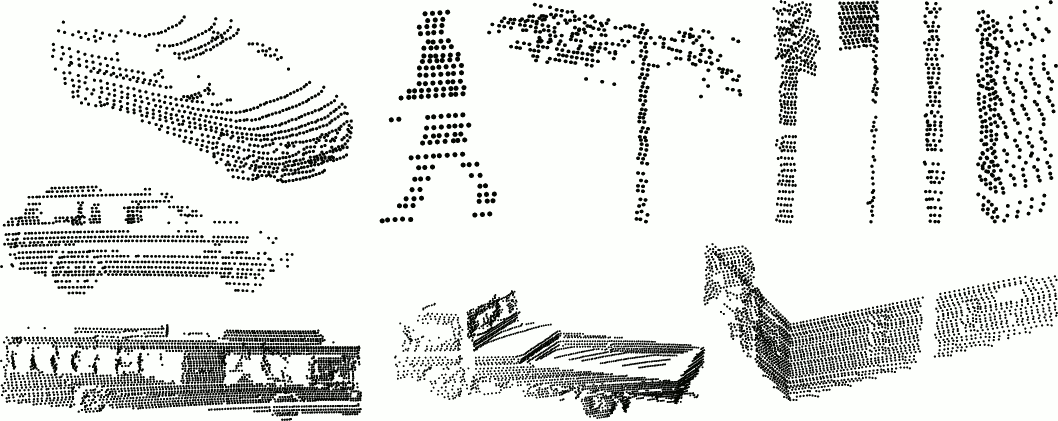
This object dataset was collected from the robot Shrimp (left), which has a Velodyne LIDAR. It spins around at 20Hz to produce a dynamic 3D point cloud of the scene. The dataset consists of 631 object instances segmented from Velodyne scans of the Sydney CBD. A few instances are shown below.
Download
objects4.tar.gz (22Mb)
Preview
View a few objects in your browser here (a recent, webgl-compatible browser is required).
Software
The ACFR has developed two open-source libraries you may find useful.
Reading the data
Each object is available in 3 formats. The simplest to read is ascii csv format (objects/*.csv). A more compact and faster-to-process format is binary csv (objects/*.bin). These both have the same fields, described in the *.meta files, which are all as follows:
| Field | Description | Format |
|---|---|---|
| t | Timestamp, microseconds since epoch | int64 |
| intensity | Laser return intensity (0-255) | uint8 |
| id | Laser id (the Velodyne has 64 lasers) | uint8 |
| x,y,z | 3D point | float32 x3 |
| azimuth | Horizontal azimuth angle, radians, calibration-corrected | float32 |
| range | Range (m) of laser return, calibration-corrected | float32 |
| pid | Point id of the original, full 360deg scan. | int32 |
These can be read in Python with Numpy, as shown in this example:
# -*- coding: utf-8 -*-
""" Simple example for loading object binary data. """
import numpy as np
names = ['t','intensity','id',
'x','y','z',
'azimuth','range','pid']
formats = ['int64', 'uint8', 'uint8',
'float32', 'float32', 'float32',
'float32', 'float32', 'int32']
binType = np.dtype( dict(names=names, formats=formats) )
data = np.fromfile('objects/excavator.0.10974.bin', binType)
# 3D points, one per row
P = np.vstack([ data['x'], data['y'], data['z'] ]).T
You can also convert binary csv to ascii csv format using comma, in a *nix terminal (or cygwin for Windows users):
cat objects/excavator.0.10974.bin | \ csv-from-bin "t,ub,ub,f,f,f,f,f,i" > excavator.0.10974.csv
With snark, you can display the points:
cat objects/excavator.0.10974.bin | \ view-points --binary "t,ub,ub,f,f,f,f,f,i" --fields t,,,x,y,z
Scans
In addition to the individual objects, the full 360deg scans are also provided, as the original velodyne data packets. Each object is named by:
[class].[instance].[scan]
For example, the segmented excavator is in objects/excavator.0.10974.bin, and the full 360deg scan that contains the excavator is in scans/scan.10974.bin. The field 'pid' indicates which points in the full scan are from the excavator.
The 'full scan' data are stored in the raw Velodyne format (8 byte timestamp in microseconds + 1206 byte packet, see the Velodyne manual). You can read this data using snark's velodyne-to-csv application. The calibration parameters for our Velodyne are in db.xml.
Classes
Only the most populous classes were used for testing classification algorithms. A reasonable set of 588 objects was selected from the full 631, split evenly into 4 folds. See folds/folds*.txt for the objects in each fold. Folds were selected to ensure no object appeared in two folds (some objects appear more than once in the dataset, scanned from different positions). This set still contains many challenging instances of highly occluded objects.
| Class | Instances |
|---|---|
| 4wd | 21 |
| bench | 2 |
| bicycle | 8 |
| biker | 4 |
| building | 20 |
| bus | 16 |
| car | 88 |
| cyclist | 3 |
| excavator | 1 |
| pedestrian | 152 |
| pillar | 20 |
| pole | 21 |
| post | 8 |
| scooter | 1 |
| ticket_machine | 3 |
| traffic_lights | 47 |
| traffic_sign | 51 |
| trailer | 1 |
| trash | 5 |
| tree | 34 |
| truck | 12 |
| trunk | 55 |
| umbrella | 5 |
| ute | 16 |
| van | 35 |
| vegetation | 2 |